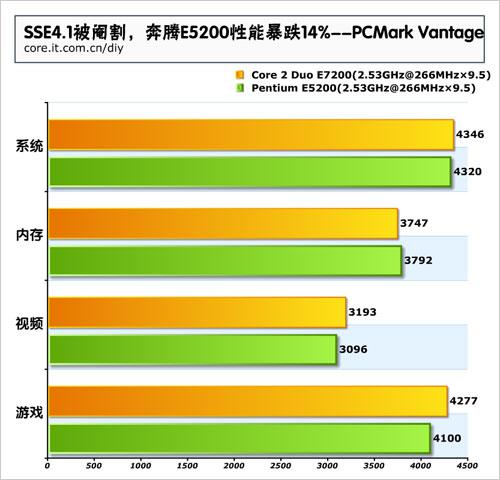
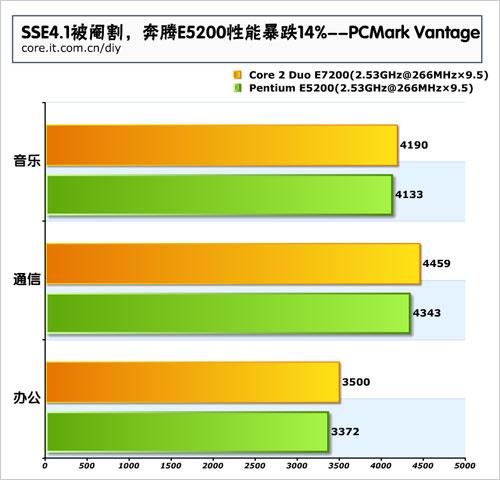
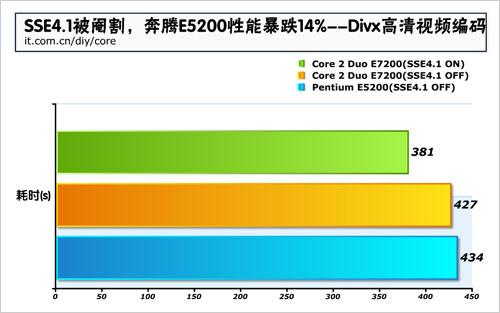
此文仅供参考
测试前言:近期Intel奔腾E5200可谓风光无限,这款超频悍将一上市就受到了玩家们的追捧,视为千元内最具购买价值的产品,超频后性能更是直追老大哥E7200。与Intel E7200相比,E5200缺失的是1M的二级缓存,0.03G的主频差距以及SEE4.1指令集的支持。就应用而言,主频的差距体现到性能上几乎可以忽略不计,1M二级缓存的差距也是微乎其微,而对于很多普通的用户而言,缺失SEE4.1指令集到底意味着什么呢?貌似在主流的应用中,SEE4.1指令集的作用并不明显。那么,SEE4.1指令集到底是不是可有可无的鸡肋呢?SEE4.1指令集是什么,缺失了SEE4.1指令集,对于E5200的性能发挥有着什么样的影响?为此,我们IT世界网CPU/存储频道特别组织了本次评测,力求在实际的应用中,为大家证明SEE4.1指令集的实用意义所在。
Intel挥刀自宫,奔腾双核E5200独缺SSE4.1
在广大玩家的热切期盼下,Intel终于发布了定位主流的45nm双核处理器,型号为奔腾双核E5200。与中高端的E8200、E7200一样,奔腾双核E5200基于45nm Wolfdale核心,主频高达2.5GHz,外频和倍频分别为200MHz和12.5X。二级缓存从E7200的3MB削减至2MB,核心内部晶体管数量则保持不变。
奔腾双核E5200高调上市,然而距离热卖还有相当距离 奔腾双核E5200伴随阉割诞生,这符合Intel削减硬件规格达到区分产品档次的习惯。然而让玩家没有想到的是,与往常削减二级缓存不同,奔腾双核E5200没有集成SSE4.1指令集。这种剥夺某种属性的做法,让人想起了被夺去了二级缓存的第一代赛扬。
按照Intel的Tick-Tock策略,45nm Prenyn架构改良自65nm Conroe架构。其中45nm工艺使晶体管数量达到4.1亿个、High-K金属栅极减少了晶体管间的漏电现象、16位除法器的增加以及加强多媒体性能SSE4.1指令集,是45nm Prenyn架构明显区别于65nm Conroe架构的主要特点。
SSE4.1指令集被阉割,奔腾双核E5200命途坎坷 不少玩家反映,奔腾双核E5200并不是严格意义上的45nm Prenyn架构处理器。那么SSE4.1指令集的缺失,会给奔腾双核E5200带来多大的性能损失,消费者有没有必要为这个指令集掏更多的腰包呢?下面,就让笔者带领大家探访一下神奇的指令集世界。
比缓存更重要,指令集的发展
处理器的运作是通过指令完成的,通过程序员编写的各式指令,处理器可以完成各种任务,因此高效的指令是提高微处理器性能的最有效途径之一。在计算机早期的发展过程中,各种程序需要相配合的指令都集成到CPU中。但是随着技术的发展,处理器集成的指令越来越多,其架构亦越发臃肿。而技术人员在研究过程中发现,约有80%的程序只用到了20%的指令。为了避免冗余的指令影响到了处理器的工作效率,精简指令集的概念诞生了。
MMX指令集的诞生,让世界进入了精彩的多媒体世界 精简指令集RISC是(Reduced Instruction Set Computing)的缩写,RISC指令集的指令数目少,而且每条指令采用相同的字节长度,一般长度为4个字节,并且在字边界上对齐,字段位置固定,特别是操作码的位置。另外,RISC指令集采用寄存器到寄存器的操作方式,只以简单的Load(读取)和Sotre(存储)操作访问内存地址。因此,每条指令中访问的内存地址不会超过1个,指令访问内存的操作不会与算术操作混在一起。精简指令集可以大大简化处理器的控制器和其他功能单元的设计。
3DNow!指令集让计算机游戏性能大幅度提高 现在的桌面处理器都基于X86指令集,为了让处理器拥有更强的性能,Intel和AMD都为其产品开发扩展指令集。MMX、SSE、SSE2、SSE3、SSSE3、3DNow!等都是我们熟悉的扩展指令集,增强了处理器在多媒体、图形图象和网络等应用的处理能力。为了方便记忆,我们通常将这些都统称为处理器的指令集。
有了这些指令集,程序员在编写软件的过程中可以直接调用相关的指令,精简了大量的语句,极大地提高了处理器的工作效率。相信熟悉处理器发展的资深玩家都记得,当年MMX指令集的采用,让奔腾处理器拥有了流畅解码VCD和MP3的能力。
术业有专攻,SSE4.1增强多媒体性能
而此次讨论的主角SSE4.1,是SSE4(Streaming SIMD Extension 4)指令集的第一个版本,Intel宣称是2001年以来最重要的媒体指令集架构的改进。除扩展Intel 64指令集架构外,还加入有关图形、视频编码及处理、三维成像及游戏应用等指令,令涉及音频、图像和数据编码算法的应用程序大幅受益。
Intel指出,加入的SSE4指令集让45nm Penryn处理器增加了2个不同的32Bit向量整数乘法运算单元,并加入8位无符号(Unsigned)最小值及最大值运算,以及16Bit及32Bit有符号 (Signed) 运算。在面对支持SSE4指令集的软件时,可以有效的改善编译器效率及提高向量化整数及单精度代码的运算能力。同时,SSE4改良插入、提取、寻找、离散、跨步负载及存储等动作,令向量运算进一步专门化。
SSE4还计入了六条浮点运算指令,支持单精度、双精度浮点运算及浮点产生操作,可立即转换其路径模式,大大减少延误,这些支持将会在3D游戏及对浮点运算能力非常敏感的领域起到积极的效果。
此外,SSE4指令集还加入了串流式负载指令,能够提升帧缓冲区的读取数据频宽,理论上可获取完整的快取缓存行,即每次读取64Bit而非8Bit,并可以将其保存在临时缓冲区内,让支持SSE4指令集的读取频宽效能提升最高至8倍。
Intel认为SSE4.1指令集能为处理器带来强大动力 SSE4指令集进一步强讯编码效果,例如可同时处理8个4-byte宽度的SAD(Sums of Absolute Differences)运算,常用于新一代高清影像编码如VC.1及H.264等规格中,令视频编码速度进一步提升。这是Intel宣称双核处理器软解高清视频,同样可以获得流畅、高质量播放效果的原因。
SSE4到底有多高效,下面这个例子可以告诉你
据了解,在进行视频编码时需要进行动态预测(Motion Estimation)及差分编码方式去除相邻2张影像之相关性,这是一个非常复杂的运算动作。在没有SSE4指令集时,完成一个步骤需要以下指令语句。
for (int moveblock=0;moveblock<16;moveblock++)
for(int line=0; line<16; line++) // Does the 16 pixels large in 4 iteration
{
int i=0;
sum0+=abs( pBlock1[j]-pBlock2)+abs(pBlock1[j+1]-pBlock2[i+1])+abs(pBlock1[j+2]-pBlock2[i+2])+abs(pBlock1[j+3]-pBlock2[i+3]); // Compare with 0 pixel offset
sum1+=abs(pBlock1[j+1]-pBlock2)+abs(pBlock1[j+2]-pBlock2[i+1])+abs(pBlock1[j+3]-pBlock2[i+2])+abs(pBlock1[j+4]-pBlock2[i+3]); // Compare with 1 pixel offset
sum2+=abs(pBlock1[j+2]-pBlock2)+abs(pBlock1[j+3]-pBlock2[i+1])+abs(pBlock1[j+4]-pBlock2[i+2])+abs(pBlock1[j+5]-pBlock2[i+3]); // Compare with 2 pixel offset
sum3+=abs(pBlock1[j+3]-pBlock2)+abs(pBlock1[j+4]-pBlock2[i+1])+abs(pBlock1[j+5]-pBlock2[i+2])+abs(pBlock1[j+6]-pBlock2[i+3]); // Compare with 3 pixel offset
sum4+=abs(pBlock1[j+4]-pBlock2)+abs(pBlock1[j+5]-pBlock2[i+1])+abs(pBlock1[j+6]-pBlock2[i+2])+abs(pBlock1[j+7]-pBlock2[i+3]); // Compare with 4 pixel offset
sum5+=abs(pBlock1[j+5]-pBlock2)+abs(pBlock1[j+6]-pBlock2[i+1])+abs(pBlock1[j+7]-pBlock2[i+2])+abs(pBlock1[j+8]-pBlock2[i+3]); // Compare with 5 pixel offset
sum6+=abs(pBlock1[j+6]-pBlock2)+abs(pBlock1[j+7]-pBlock2[i+1])+abs(pBlock1[j+8]-pBlock2[i+2])+abs(pBlock1[j+9]-pBlock2[i+3]); // Compare with 6 pixel offset
sum7+=abs(pBlock1[j+7]-pBlock2)+abs(pBlock1[j+8]-pBlock2[i+1])+abs(pBlock1[j+9]-pBlock2[i+2])+abs(pBlock1[j+10]-pBlock2[i+3]); // Compare with 7 pixel offset
i=4;
j=moveblock+4;
…
… }
}
一大串的指令极度浪费处理器资源,而在支持SSE4指令集的处理器上,只需要采用4 SAD运算指令:
MPSADBW xmm0,xmm1,0
便完全代替了以上繁复的指令串,大幅提升动态预测(Motion Estimation)及差分编码的运算速度。
可以看到,SSE4指令集可以大大提高处理器的工作效率。而对于程序员来说,编写基于SSE4指令集的软件不但节省精力,而且可以获得更为高效的软件产品。那么SSE4.1的缺阵,会给奔腾双核E5200带来怎样的性能影响呢?
[ 本帖最后由 共相语 于 2008-9-19 06:59 编辑 ] | 

 IP卡
IP卡 狗仔卡
狗仔卡 发表于 2008-9-19 06:56:27
发表于 2008-9-19 06:56:27

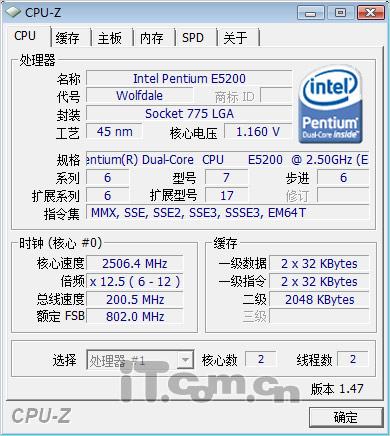




 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 显身卡
显身卡 楼主
楼主